Introduction
Large language models (LLMs) increasingly rely on step-by-step reasoning for various applications, yet their reasoning processes remain poorly understood, hindering research, development, and safety efforts. To address this, we introduce Landscape of Thoughts, the first visualization tool designed to explore the reasoning paths of chain-of-thought and its derivatives across any multiple-choice dataset. We represent reasoning states as feature vectors, capturing their distances to all answer choices, and visualize them in 2D using t-SNE. Through qualitative and quantitative analysis, Landscape of Thoughts effectively distinguishes strong versus weak models, correct versus incorrect answers, and diverse reasoning tasks. It also reveals undesirable reasoning patterns, such as inconsistency and high uncertainty. Furthermore, users can adapt the tool to predict specific properties, as demonstrated by a lightweight verifier that evaluates reasoning correctness.
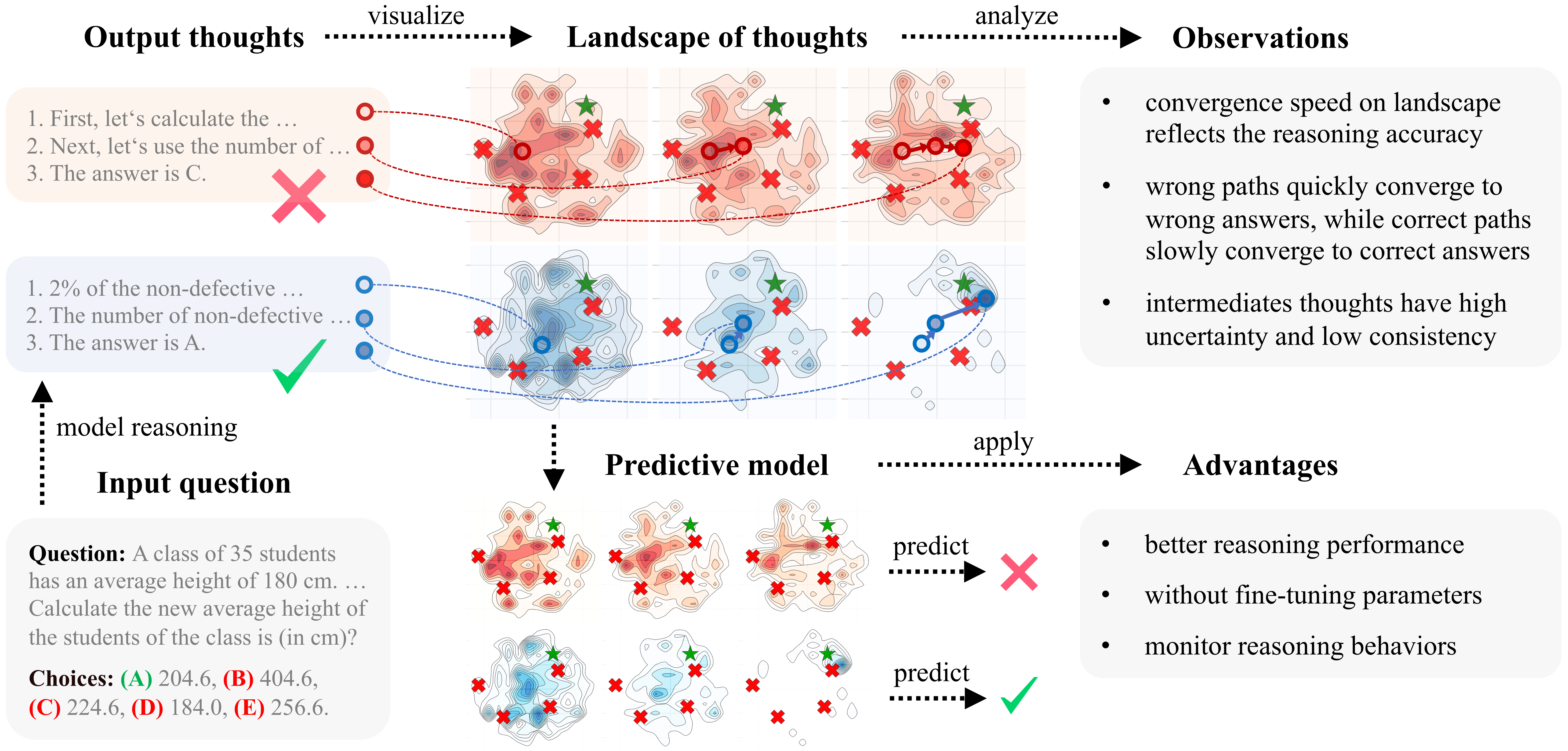
Figure 1. Illustration of Landscape of thoughts for visualizing the reasoning steps of LLMs. Note that the red landscape represents wrong reasoning cases, while the blue indicates the correct ones. The darker regions in landscapes indicate more thoughts, with  indicating incorrect answers and
indicating incorrect answers and  marking correct answers.
We sample reasoning trajectories from an LLM, segment them into individual thoughts, categorize them based on their correctness, and project them into a 2-dimensional space to visualize how reasoning states are distributed throughout the solution process.
marking correct answers.
We sample reasoning trajectories from an LLM, segment them into individual thoughts, categorize them based on their correctness, and project them into a 2-dimensional space to visualize how reasoning states are distributed throughout the solution process.
Examples of Visualization
We show the examples of landscape of thoughts: visualization of AQuA using Llama-3.1-70B across different reasoning methods.
Chain-of-Thought (CoT)
Least-to-Most (L2M)
Tree-of-Thought (ToT)
Monte Carlo Tree Search (MCTS)
Landscape of Thoughts
The visualization of the reasoning process can be conducted by the following steps.
- Characterizing the states: We characterize intermediate thoughts, measure their distances to possible choices in a unified feature space.
- Visualization: We project the high-dimensional feature matrix into 2D space, and smooth the discrete points into a continuous density map.
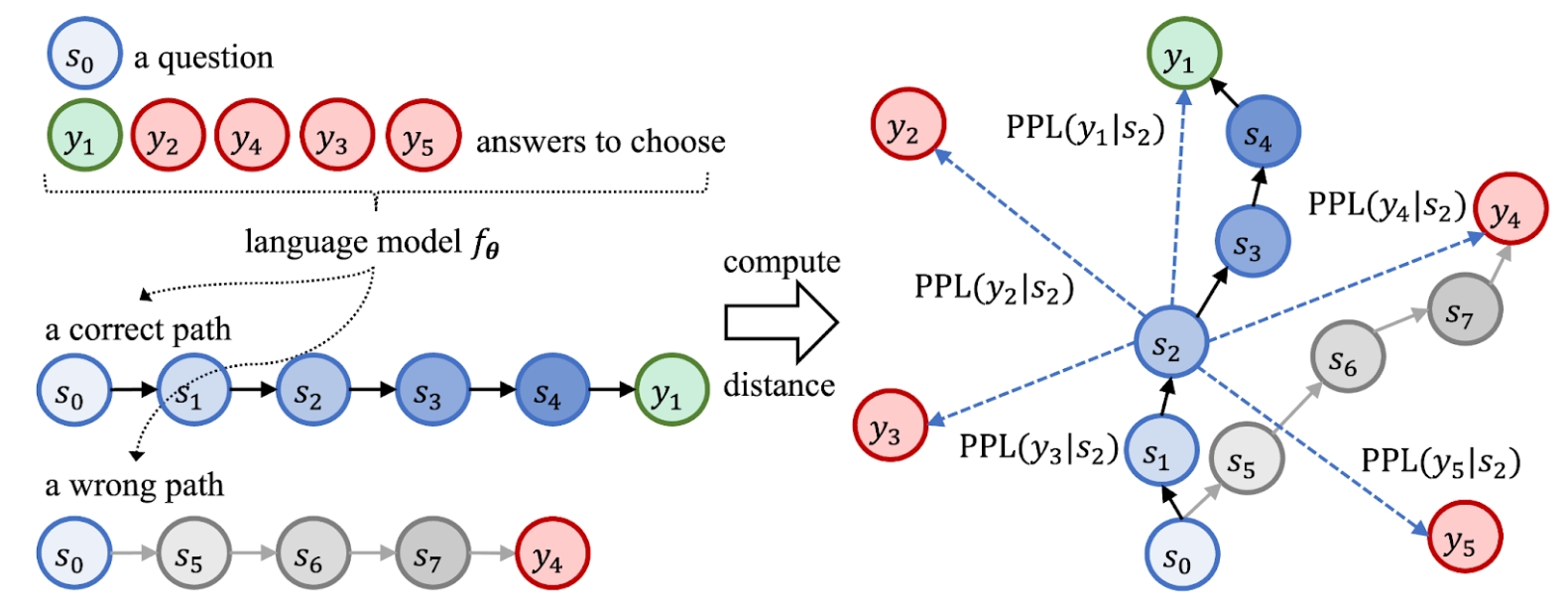
Figure 2. Implementation details of Landscape of Thoughts.
In addition, we also introduce three quantitative metrics to help understand the reasoning behaviors of LLMs at different steps.
- Consistency: whether the LLM knows the answer before generating all thoughts:
- Uncertainty: how confident the LLM is about its predictions at intermediate steps:
- Perplexity: how confident the LLM is about its thoughts:
Visualization Experiments
We analyze the landscape of thoughts across different methods, datasets and LLMs.
Different Algorithms
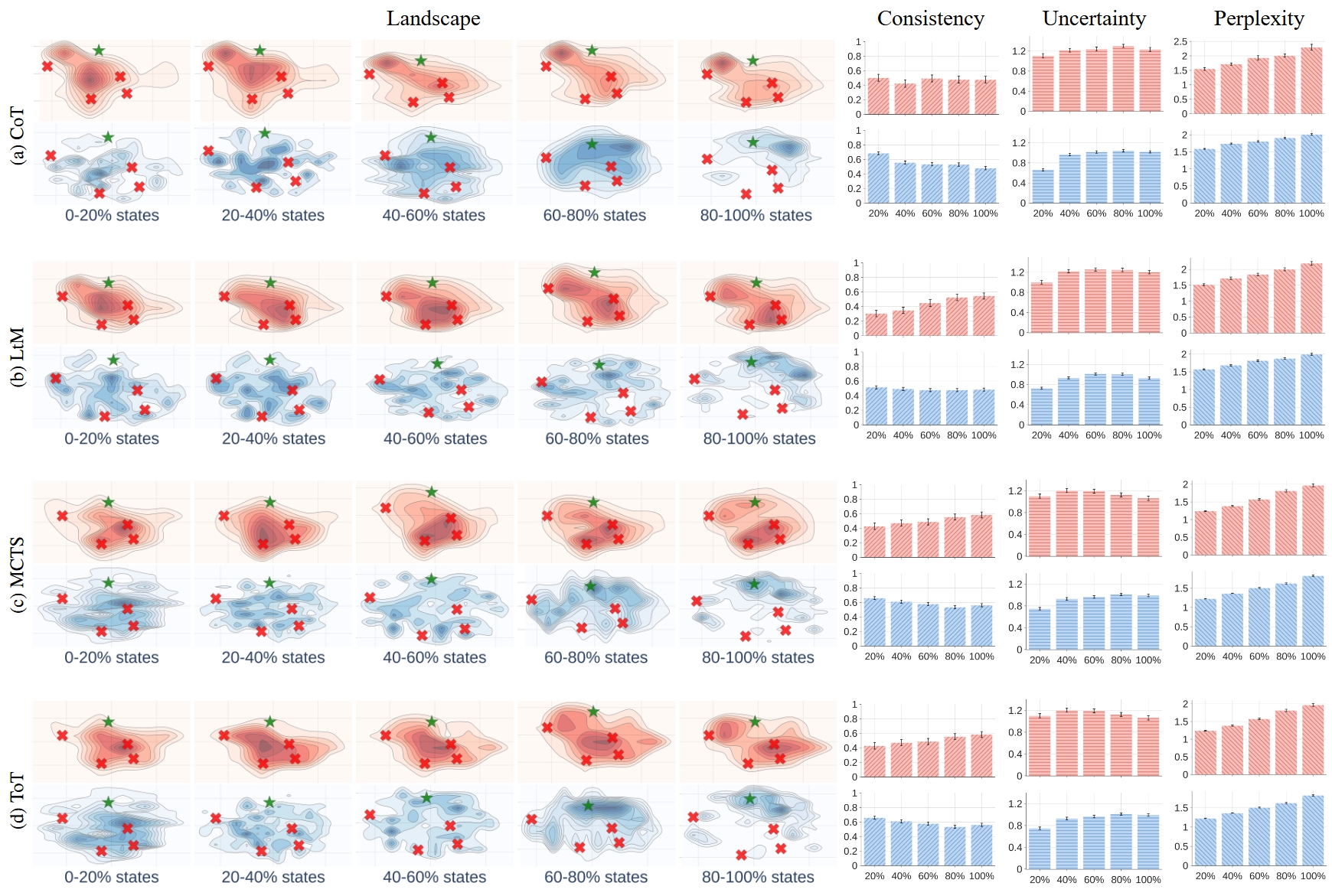
Figure 3. Comparing the landscapes and corresponding metrics of four reasoning algorithms (using Llama-3.1-70B on the AQuA dataset).
We can use Landscape of Thoughts to analyze the reasoning process of different algorithms.
- Observation 1: Faster landscape convergence indicates higher reasoning accuracy.
- Observation 2: Wrong paths converge quickly, correct paths progress slowly.
- Observation 3: Correct paths show higher consistency between intermediate and final states.
Different Datasets
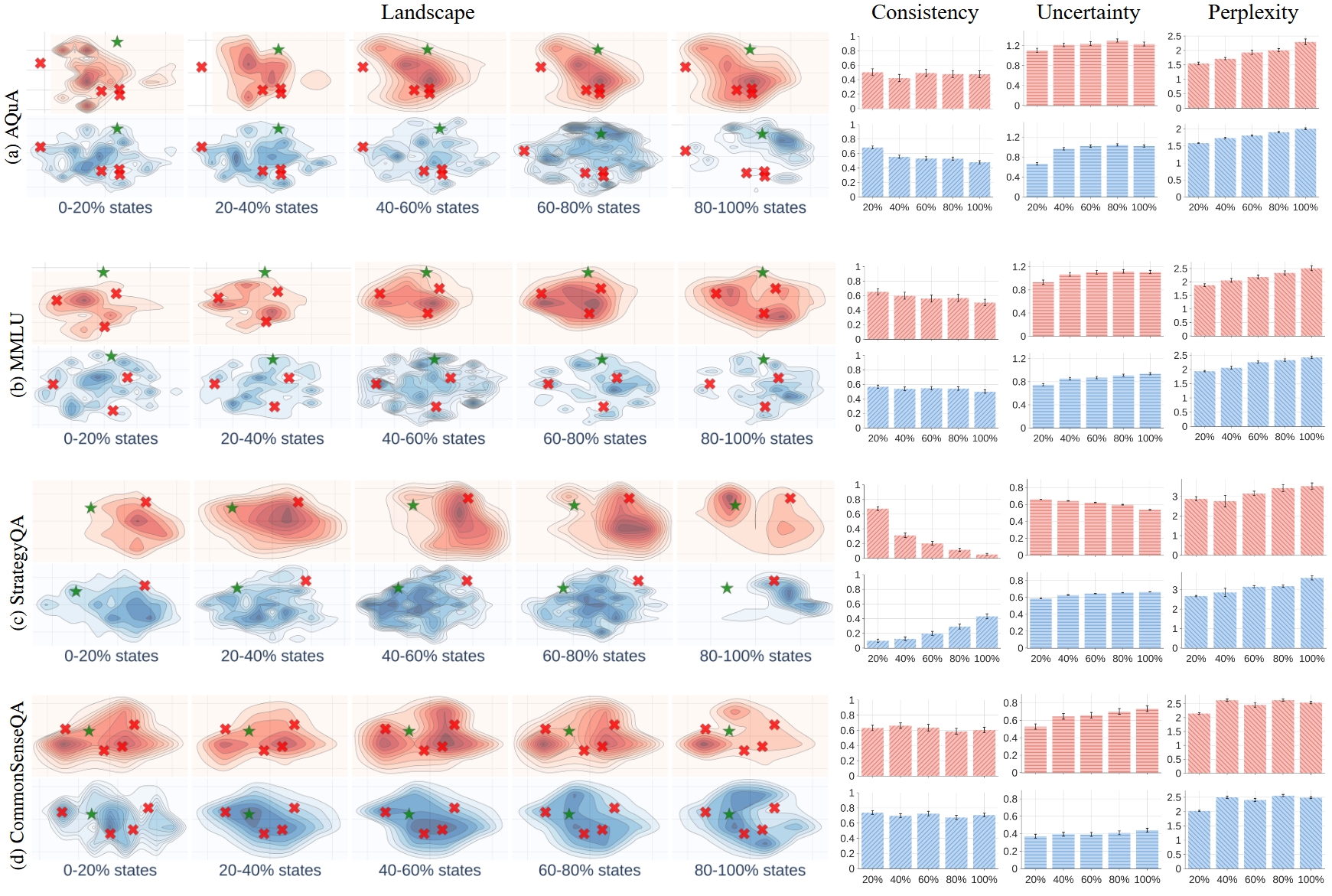
Figure 4. Comparing the landscapes and corresponding metrics of different datasets (using Llama-3.1-70B with CoT).
We can use Landscape of Thoughts to analyze the reasoning process of different datasets.
- Observation 4: Similar reasoning tasks exhibit similar landscapes.
- Observation 5: Different reasoning tasks show different consistency, uncertainty, and perplexity.
Non-reasoning Models
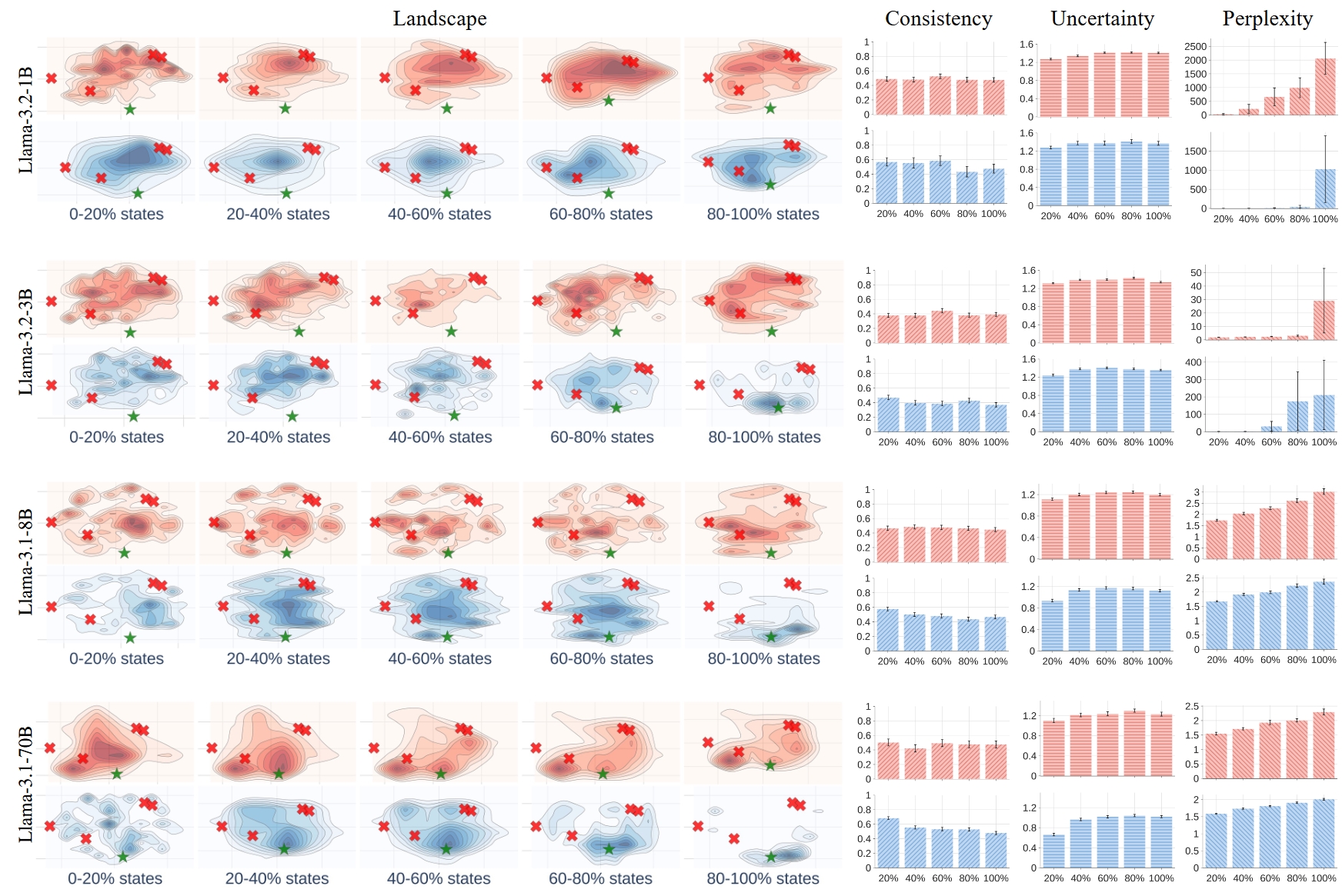
Figure 5. Comparing the landscapes and corresponding metrics of different language models (with CoT on the AQuA dataset).
We can use Landscape of Thoughts to analyze the reasoning process of different models.
- Observation 6: The landscape converges faster as the model size increase.
- Observation 7: Larger models have higher consistency, lower uncertainty, and lower perplexity.
Reasoning Models
We present visualizations of the reasoning process for several advanced language models. Specifically, we analyze the CoT reasoning patterns of QwQ-32B, DeepSeek-R1-Distilled-Llama-70B, and DeepSeek-R1-Distilled-Qwen-1.5B on the AQuA dataset.
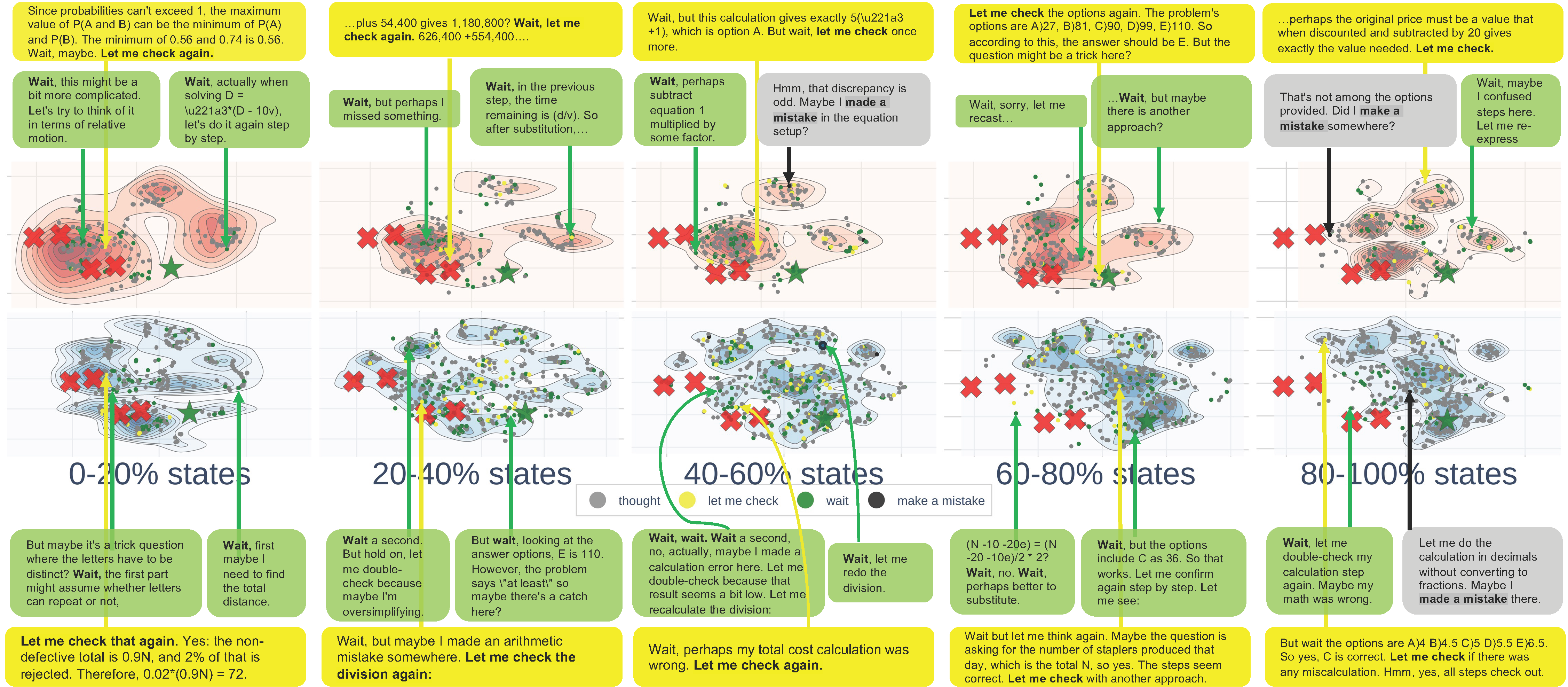
Figure 6. Landscape of QwQ-32B using CoT on AQuA.
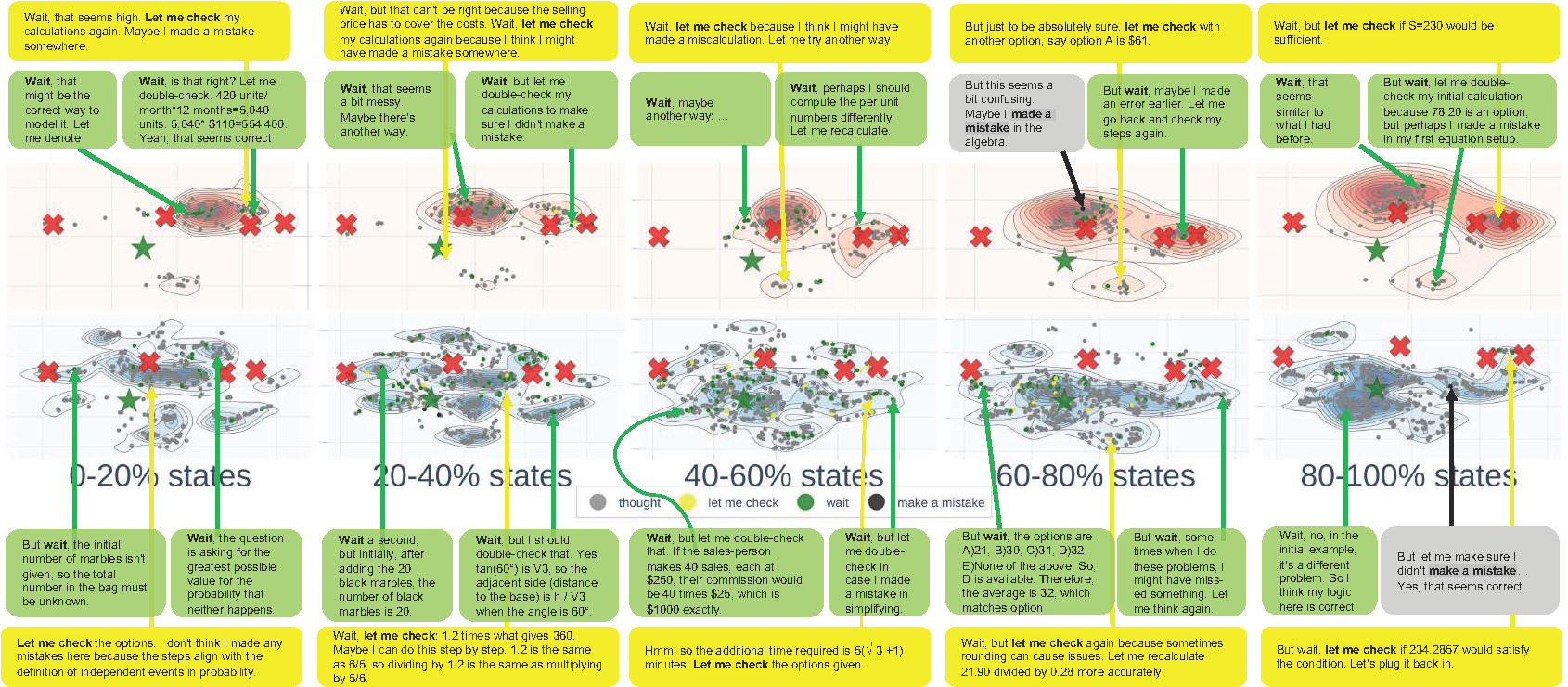
Figure 7. Landscape of DeepSeek-R1-Distilled-Llama-70B using CoT on AQuA.
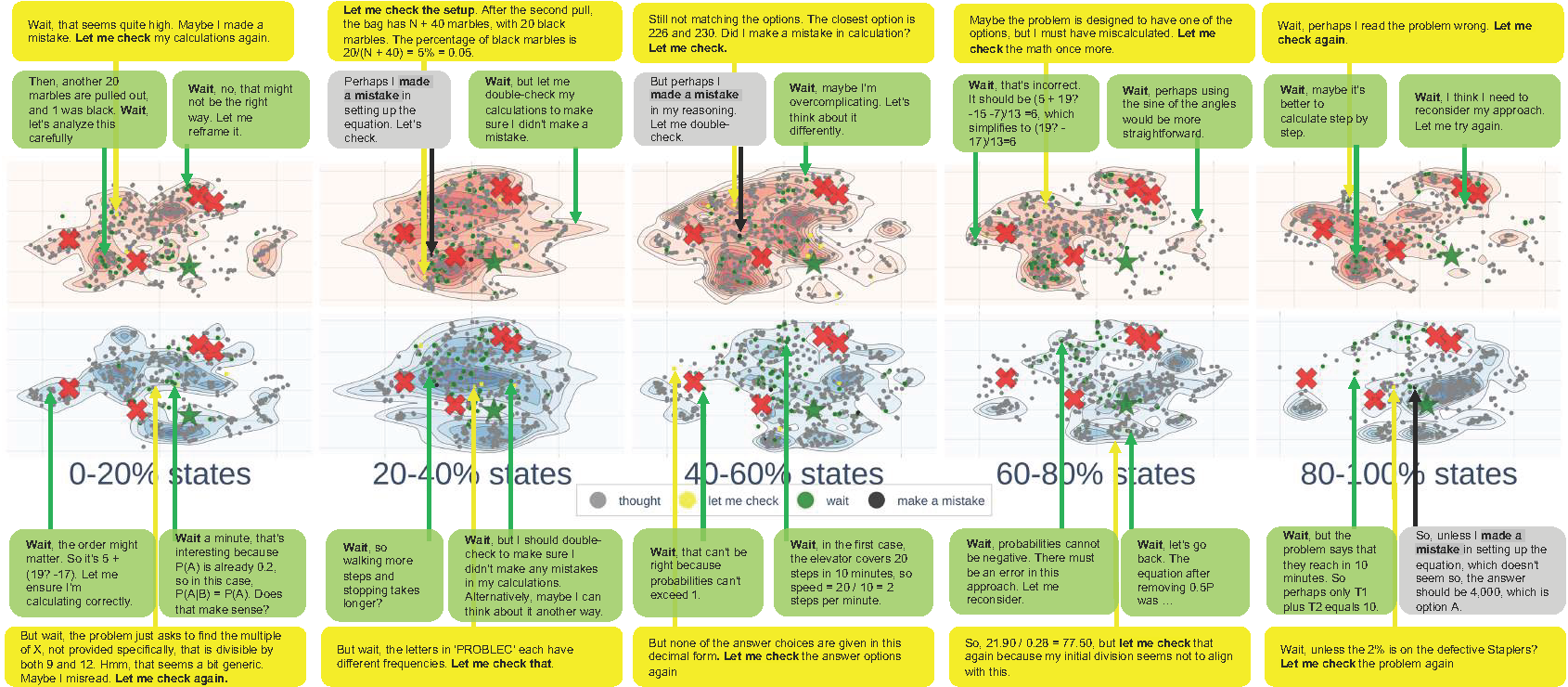
Figure 8. Landscape of DeepSeek-R1-Distilled-Qwen-1.5B using CoT on AQuA.
- Observation 8: Correct reasoning demonstrates decentralized patterns.
- Observation 9: Reasoning models exhibit self-checking and awareness of correctness when deviating from the correct answer.
A Lightweight Verifier to Predictive Models
Based on the observations from visualization, the landscape of thoughts method has the potential to be adapted to a model to predict any property users observe, here we show examples of using it to predict the correctness of the reasoning paths.
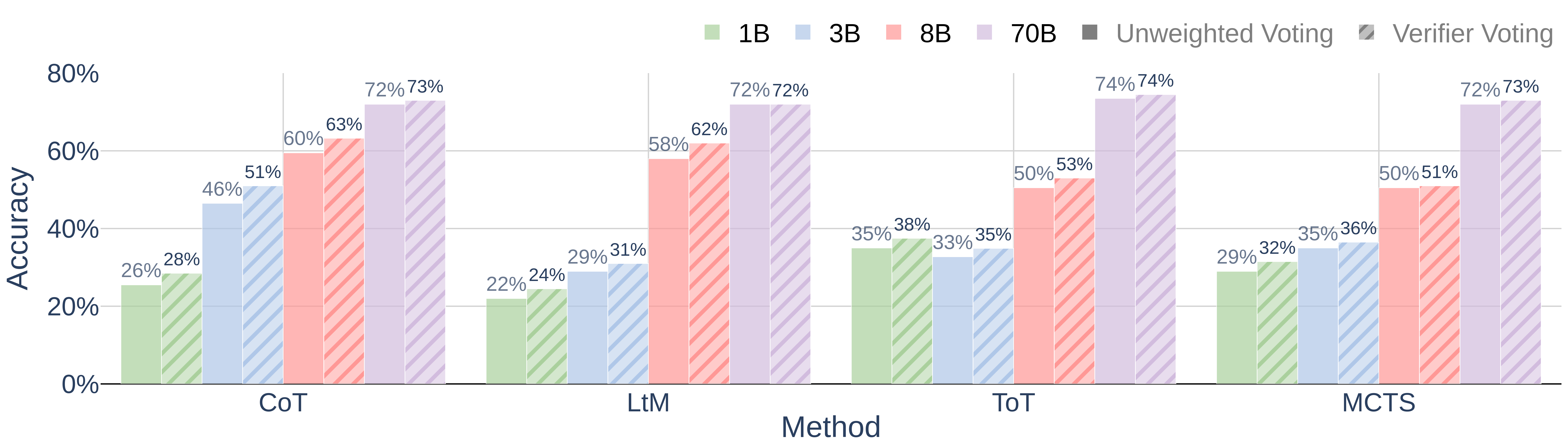
Figure 9. Reasoning accuracy averaging across all dataset.
Then, we investigate the inference-time scaling effect of the verifier by adjusting the number of reasoning paths.
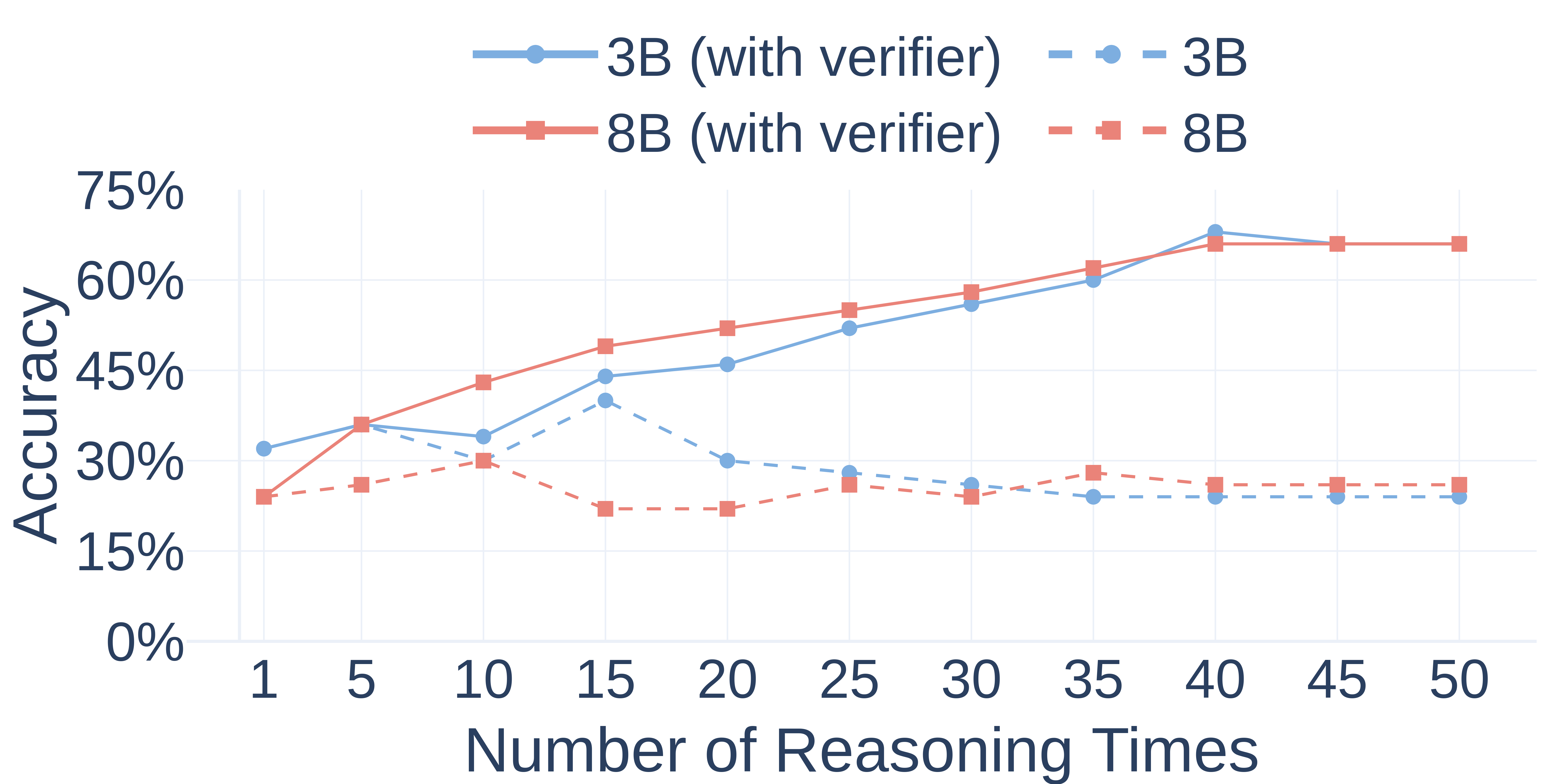
Figure 10. Demonstration of the inference-time scaling effect of the verifier.
Notably, this verifier serves as a simple demonstration of how the Landscape of Thoughts framework can be leveraged to improve language models' reasoning capabilities. The framework can be extended to many other scenarios, enabling the discovery and analysis of additional interesting properties of language model reasoning.
Contact & Citation
For more details about our work, please refer to our paper. If you have any questions, feel free to contact us at cszkzhou@comp.hkbu.edu.hk or open an issue on our GitHub repository.
If you find our paper and repo useful, please consider to cite:
@article{zhou2025landscape,
title={Landscape of Thoughts: Visualizing the Reasoning Process of Large Language Models},
author={Zhou, Zhanke and Zhu, Zhaocheng and Li, Xuan and Galkin, Mikhail and Feng, Xiao and Koyejo, Sanmi and Tang, Jian and Han, Bo},
journal={arXiv preprint arXiv:2503.22165},
year={2025},
url={https://arxiv.org/abs/2503.22165}
}